Najważniejsze pojęcia bazodanowe
Język zapytań SQL zawsze pojawia się na egzaminie zawodowym – nawet jeżeli zadanie będzie polegać na stworzeniu skryptu JavaScript po stronie klienta, to zazwyczaj i tak trzeba będzie także zapisać cztery kwerendy różnego rodzaju w pliku tekstowym. Oczywiście w przypadku zadania realizowanego w języku PHP po stronie serwera, to naturalnie przyjdzie nam stworzyć kilka zapytań. Zanim zaczniemy powtórkę rodzajów zapytań, klauzul oraz sposobów operowania danymi, to musimy zrealizować podsumowanie podstawowych pojęć związanych z bazami danych. Przejdźmy zatem do podsumowania fundamentów, podamy też nieco teorii bazodanowej pod egzamin teoretyczny.
Baza danych
Baza danych to nic innego jak uporządkowany zbiór danych (informacji), który przechowujemy w uporządkowany sposób – zazwyczaj zorganizowany jako zestaw powiązanych ze sobą tabel. Organizacja pozwala łatwo zarządzać danymi, wyszukiwać je, dodawać nowe i usuwać istniejące. Możemy sobie to wyobrazić jako elektroniczny odpowiednik segregatora z dokumentami, gdzie każda strona zawiera jakieś konkretne informacje. Kiedy zajmujemy się tworzeniem takich wielkich zbiorów danych, to tak naprawdę “modelujemy” rzeczywistość – tworzymy model, czyli abstrakcyjną, wirtualną reprezentację rzeczywistego świata.
Baz danych używamy na przykład:
- Podczas logowania się do dowolnego serwisu social-mediowego – dane użytkowników oraz tworzone przez nich cyfrowe treści są przechowywane w bazie.
- Gdy przeglądamy filmy w usłudze streamingowej (YouTube, Netflix, Disney+, Prime Video) – aplikacja pobiera katalog proponowanych filmów z bazy danych.
- Gdy kupujemy coś w sklepie internetowym – informacje o produktach, zamówieniach i klientach są trzymane w bazie.
Język SQL
Jest to strukturalny język zapytań kierowanych do baz danych – skrót SQL pochodzi od ang. Structured Query Language. Opracowała go firma IBM w latach 70. XX wieku – oczywiście przeszedł od tego czasu sporo modyfikacji, ale stał się podstawowym standardem w komunikacji z relacyjnymi bazami danych. SQL jest językiem deklaratywnym, a nie imperatywnym – oznacza to w praktyce, iż zadaniem programisty jest jedynie opisać warunki, jakie musi spełniać końcowe rozwiązanie (“co chcemy osiągnąć”), a nie szczegółowo zaimplementować algorytm, który do niego prowadzi (“jak to zrobić”). I rzeczywiście praca z danymi w SQL ma naturę zdecydowanie deklaratywną.
Czasem też padają na testach pytania o tzw. cztery główne podzbiory języka SQL – przedstawmy je:
- SQL DCL (ang. Data Control Language) – język kontrolowania danymi (GRANT, REVOKE).
- SQL DDL (ang. Data Definition Language) – język definiowania danych (CREATE, ALTER).
- SQL DML (ang. Data Manipulation Language) – język manipulowania danymi (INSERT, UPDATE).
- SQL DQL (ang. Data Query Language) – język definiowania zapytań (SELECT).
DBMS
Jedna z fundamentalnych definicji bazodanowych, pojawiająca się w wielu testach i zadaniach. Skrót ten oznacza:
- DBMS – ang. Database Management System
- SZBD – to samo w wersji polskiej: System Zarządzania Bazą Danych
Zatem DBMS to oprogramowanie zarządzania bazami danych, które daje nam (między innymi) możliwości:
- zarządzania użytkownikami systemu bazodanowego, w tym obsługę wbudowanych mechanizmów autoryzacji i walidacji uprawnień,
- ochrony integralności (spójności) zbioru danych – zapewnienie poprawności, dokładności i aktualności zbioru informacji,
- wykonywania na zgromadzonych danych kwerend (zapytań w języku SQL),
- zapewnienia bezpieczeństwa i trwałości danych, w tym mechanizmów tworzenia oraz odzyskiwania kopii zbioru informacji.
Przykładowe współczesne systemy DBMS to:
- MariaDB (od MariaDB Foundation),
- MySQL (od firmy Oracle),
- PostgreSQL (opracowany na uniwersytecie w Berkeley),
- FireBird (korporacja Borland),
- MS SQL Server (od Microsoft).
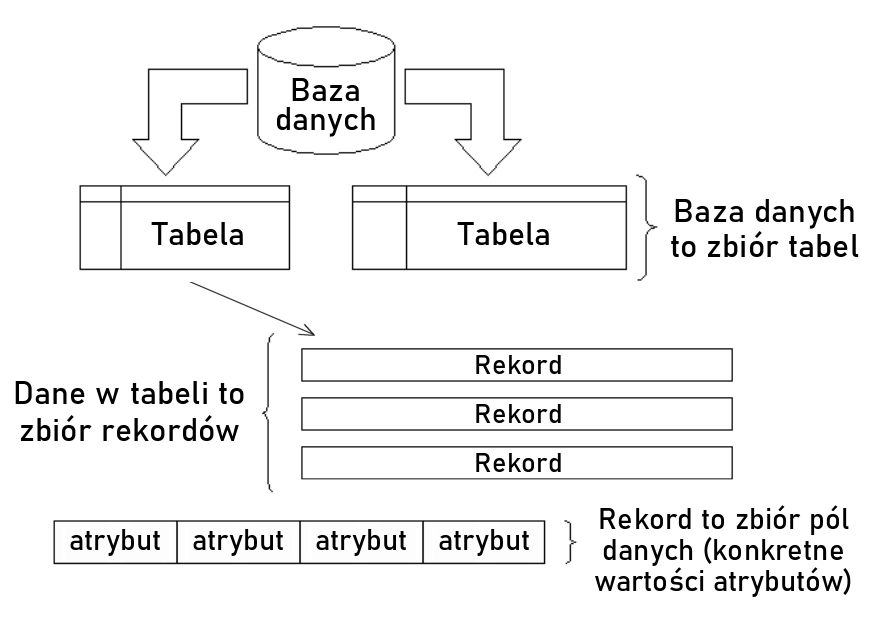
Tabela, atrybut, rekord, encja
Najważniejszym elementem w relacyjnej bazie danych jest tabela – to tutaj przechowujemy wszystkie informacje w postaci wierszy i kolumn. Posłużmy się przykładem. Informacje o filmach przechowywanych w bazie danych usługi vod (ang. video on demand), zostały umieszczone w następującej tabeli:
Tabela filmy
| ID_filmu | Tytul | Kraj_produkcji | Gatunek | Cena_w_zl |
|---|---|---|---|---|
| AA2003 | Kill Bill | USA | thriller | 6 |
| AC1992 | Ojciec chrzestny | USA | dramat | 5 |
| CD2001 | Kompania braci | Wielka Brytania | wojenny | 7 |
Rekord (krotka, ang. tuple) to pojedynczy wiersz w tabeli, czyli zestaw wartości atrybutów przypisanych danemu obiektowi. W tabeli wyżej rekordem jest film, czyli zestaw cech złożonych łącznie z identyfikatora, tytułu, kraju produkcji, gatunku filmowego oraz ceny wypożyczenia. Wartości wszystkich tych – w tym przypadku pięciu – atrybutów, stanowią jeden rekord tabeli.
Atrybut (cecha, właściwość) – to kolumna w tabeli, przechowująca jakąś cechę obiektu (rekordu) – np. Gatunek, który określa rodzaj (klimat) filmu.
Pole to komórka tabeli przechowująca dane określonego typu – na przykład liczbę, napis, czas, datę albo wartość logiczną. W pokazanej tabeli jest to każda pojedyncza wartość kolumny (atrybutu), np. wartość USA atrybutu Kraj_produkcji czy wartość Kill Bill dla atrybutu Tytul.
Zestaw atrybutów opisujący w modelu dany rekord (tutaj jest nim film) w programowaniu oraz nomenklaturze bazodanowej często określamy mianem encji lub ewentualnie klasy. Konkretnego reprezentanta (przedstawiciela) tej klasy nazywamy zaś instancją.
Reasumując – ideowy schemat “budowy” relacyjnej bazy danych prezentuje się następująco:
Kwerenda
Z języka ang. query – inaczej zapytanie do bazy danych. Istnieje wiele rodzajów zapytań, m.in: kwerendy wybierające, aktualizujące, usuwające, dołączające, krzyżowe, tworzące tabele etc. W teorii bazodanowej spotkamy także czasem akronim CRUD oznaczający cztery podstawowe operacje implementowane w aplikacjach bazodanowych:
- Create – w SQL np. kwerenda INSERT
- Read (albo ewentualnie Retrieve) – w SQL np. kwerenda SELECT
- Update – w SQL np. kwerenda UPDATE
- Delete (albo ewentualnie Destroy) – w SQL np. kwerenda DELETE
Różnorodność słów opisujących zagadnienia związane z bazami danych jest ogromna i może na początku nieco przerażać – w celu usystematyzowania mnogości pojęć, posłużmy się następującym zestawieniem “słów, których można używać zamiennie”:
| Termin bazodanowy | Teoria relacyjna (Edgar Frank Codd) | Teoria związków encji (Peter Chen) | Programowanie obiektowe |
|---|---|---|---|
| tabela | relacja | encja | klasa |
| rekord, wiersz (ang. row) | krotka (ang. tuple) | instancja | obiekt |
| atrybut, kolumna | atrybut | atrybut | atrybut, właściwość, cecha |
W zależności od preferencji osoby albo kontekstu wypowiedzi, te same pojęcia mogą być nieco inaczej określane przez różnych ludzi. Wbrew pozorom często może to mieć miejsce – na przykład cecha obiektu w HTML to “atrybut”, lecz cecha obiektu w języku CSS to już “właściwość”. Różne słowa, lecz esencjonalne znaczenie takie samo. I całkiem podobnie bywa w bazach danych.
XAMPP
Jest to darmowy, gotowy do użycia pakiet oprogramowania pozwalający szybko uruchomić lokalny serwer internetowy – dzięki temu możemy tworzyć i testować własne strony internetowe bez konieczności posiadania zewnętrznego serwera i domeny.
Skrót XAMPP pochodzi od:
- X = “krzyżyk” (aluzja do ang. cross-platform) – oprogramowanie wieloplatformowe (Win / MacOS / Linux),
- A = Apache (serwer www),
- M = MariaDB – system zarządzania bazami danych, w tym phpMyAdmin – panel webowy do zarządzania bazami danych przez przeglądarkę,
- P = PHP – interpreter tego języka,
- P = Perl – język do tworzenia tzw. skryptów CGI na serwerze.
Oprogramowanie XAMPP odnajdziemy oczywiście także na stanowisku egzaminacyjnym INF.03.
Klucz główny (ang. primary key)
Każda tabela powinna mieć unikalny identyfikator dla każdego wiersza (rekordu). I właśnie klucz główny (ang. primary key) albo inaczej klucz podstawowy to specjalna kolumna (lub ewentualnie zestaw kolumn) w tabeli bazy danych, która jednoznacznie identyfikuje każdy wiersz. Dzięki wartości klucza głównego wiemy, który konkretny rekord (wiersz w tabeli) przetwarzamy i możemy go jednoznacznie odszukać.
Przykładowa definicja klucza głównego w kwerendzie tworzącej tabelę z filmami:
CREATE TABLE filmy (
ID_filmu VARCHAR(6) PRIMARY KEY,
Tytul TEXT NOT NULL,
Gatunek TEXT NOT NULL,
Cena_w_zl INT NOT NULL
);
Tabela filmy, klucz główny to atrybut (kolumna) ID_filmu:
| ID_filmu | Tytul | Kraj_produkcji | Gatunek | Cena_w_zl |
|---|---|---|---|---|
| AA2003 | Kill Bill | USA | thriller | 6 |
| AC1992 | Ojciec chrzestny | USA | dramat | 5 |
| CD2001 | Kompania braci | Wielka Brytania | wojenny | 7 |
Najważniejsze cechy klucza głównego:
-
Unikalność – każda wartość w kolumnie będącej kluczem głównym musi być unikalna – nie mogą istnieć dwa filmy o takiej samej wartości w kolumnie
ID_filmu. -
Wartość klucza nie może być pusta (NULL) – bo wówczas nie uda się zidentyfikować czegoś w sposób jednoznaczny.
-
W jednej tabeli może istnieć tylko jeden klucz główny.
- Możliwe jest ustawienie dla klucza głównego właściwości
AUTO_INCREMENT, która spowoduje automatyczne zwiększanie wartości klucza dla nowych rekordów (jeśli tylko klucz jest typu numerycznego). Wówczas podczas wstawiania do tabeli nowego rekordu z użyciem zapytania INSERT możemy pozostawić wartość klucza pustą – system sam wybierze pierwszą wolną (nową oraz unikalną) wartość klucza.
Klucz obcy (ang. foreign key)
Jest to kolumna (lub zestaw kolumn) w jednej tabeli, która odwołuje się do istniejącego klucza głównego, reprezentującego rekord w innej tabeli. Dzięki tym powiązaniom logicznym (potocznie nazywanymi relacjami) możemy oddać istniejące powiązania np. między zamówieniem a klientem, wypożyczeniem a filmem, uczniem i klasą.
Przykładem klucza obcego jest kolumna ID_filmu w tabeli wypozyczenia odnosząca się do konkretnego rekordu (filmu) w tabeli filmy:
Tabela wypozyczenia, klucz obcy ID_filmu stanowiący odwołanie do rekordu z innej tabeli:
| ID_wyp | Data_wyp | ID_filmu | Pesel |
|---|---|---|---|
| 458 | 2011-12-09 | AA2003 | 78061600937 |
Tabela filmy, klucz główny ID_filmu, jednoznacznie identyfikujący rekord:
| ID_filmu | Tytul | Kraj_produkcji | Gatunek | Cena_w_zl |
|---|---|---|---|---|
| AA2003 | Kill Bill | USA | thriller | 6 |
| AC1992 | Ojciec chrzestny | USA | dramat | 5 |
| CD2001 | Kompania braci | Wielka Brytania | wojenny | 7 |
Wypożyczenie 458 dotyczyło filmu o identyfikatorze ID_filmu równym AA2003, czyli jak się okazało w tabeli filmy – produkcji Kill Bill (USA, thriller) w cenie 6 zł. Innymi słowy możemy stwierdzić, iż dla tych tabel (dla powiązanych logicznie rekordów) zachodzi równość: wypozyczenia.ID_filmu = filmy.ID_filmu.
Definicja klucza obcego w języku SQL podczas tworzenia tabeli wypozyczenia z użyciem zapytania CREATE:
CREATE TABLE wypozyczenia (
ID_wypozyczenia INT PRIMARY KEY AUTO_INCREMENT,
ID_filmu VARCHAR(6),
Pesel_klienta VARCHAR(11),
Data_wypozyczenia DATE,
FOREIGN KEY (ID_filmu) REFERENCES filmy(ID_filmu)
);
Po co istnieją klucze obce?
- Łączą dane z różnych tabel w logiczną całość (np. kojarzą logicznie zamówienie z klientem i zakupionym produktem).
- Zachowują spójność (integralność) danych, czyli zgodność z rzeczywistością (np. kto, kiedy, za ile oraz co dokładnie w internetowym sklepie zamówił).
- Umożliwiają łączenie danych (JOIN) podczas zapytań SQL.
Rodzaje relacji (powiązań) logicznych
Zwróćmy też uwagę, iż w powyższym przykładzie z kluczem obcym może nastąpić wiele wypożyczeń tego konkretnego filmu w tabeli wypożyczenia (czyli wartość AA2003 może się wiele razy powtórzyć w tabeli wypozyczenia w kolumnie ID_filmu), natomiast w tabeli filmy wartość AA2003 może wystąpić tylko i wyłącznie raz. Jest to w końcu klucz główny! – nie mogą istnieć dwa filmy o takim samym identyfikatorze (reguła unikalności). Taki rodzaj relacji pomiędzy kluczem głównym a obcym nazywamy relacją typu “jeden do wielu”.
Klasyczne rodzaje relacji logicznych:
- Jeden do jednego (1:1) – każdemu rekordowi z jednej tabeli odpowiada dokładnie jeden rekord z drugiej tabeli. I odwrotnie – każdemu rekordowi z drugiej tabeli odpowiada dokładnie jeden rekord z pierwszej. Każdy użytkownik ma swój numer PESEL przypisany w aptece online. I każdy zapisany numer PESEL należy tylko do jednego użytkownika.
- Jeden do wielu (1:N) – jeden rekord w pierwszej tabeli może być powiązany z wieloma rekordami w drugiej tabeli. Lecz każdy rekord w drugiej tabeli odnosi się tylko do jednego rekordu w pierwszej. Przykład to film wypożyczany wielokrotnie, lecz istniejący tylko jeden raz (jako jeden rekord) w tabeli przechowującej filmy.
- Wiele do wielu (N:M) – wiele rekordów z jednej tabeli może być powiązanych z wieloma rekordami z drugiej tabeli. I odwrotnie. Na przykład jeden uczeń może uczęszczać na wiele przedmiotów w szkole oraz każdy przedmiot może być uczęszczany przez wielu uczniów.
Typy danych w SQL
Zobaczmy teraz przypomnienie najczęściej używanych w tabelach typów danych atrybutów (kolumn):
| Typ danych | Opis i zakres wartości |
|---|---|
TINYINT |
Liczba całkowita (1 bajt). Zakres: -128 do 127 lub 0–255 (UNSIGNED). |
SMALLINT |
Liczba całkowita (2 bajty). Zakres: -32768 do 32767 lub 0–65535 (UNSIGNED). |
MEDIUMINT |
Liczba całkowita (3 bajty). Zakres: -8388608 do 8388607 lub 0–16777215. |
INT / INTEGER |
Liczba całkowita (4 bajty). Zakres: -2147483648 do 2147483647 lub 0–4294967295. |
BIGINT |
Duża liczba całkowita (8 bajtów). Zakres: -2^63 do 2^63-1 lub 0–2^64-1. |
DECIMAL(p,s) |
Liczba dziesiętna o stałej precyzji. Np. DECIMAL(10,2) = do 99999999.99. |
FLOAT |
Liczba zmiennoprzecinkowa (4 bajty). Zakres zbliżony do ±3.4E38. |
DOUBLE |
Liczba zmiennoprzecinkowa (8 bajtów). Zakres do ±1.7E308. |
CHAR(n) |
Tekst o stałej długości do 255 znaków. |
VARCHAR(n) |
Tekst o zmiennej długości. Maksymalnie 65535 bajtów (w zależności od kodowania). |
TINYTEXT |
Mały tekst, maksymalnie 255 znaków. |
TEXT |
Tekst do 65535 znaków. |
MEDIUMTEXT |
Tekst do 16777215 znaków (~16 MB). |
LONGTEXT |
Tekst do 4294967295 znaków (~4 GB). |
DATE |
Data w formacie YYYY-MM-DD. Zakres: 1000-01-01 do 9999-12-31. |
DATETIME |
Data i czas YYYY-MM-DD HH:MM:SS. Zakres: 1000-01-01 00:00:00 do 9999-12-31 23:59:59. |
TIME |
Czas HH:MM:SS. Zakres: -838:59:59 do 838:59:59. |
TIMESTAMP |
Znacznik czasu. Zakres: 1970-01-01 00:00:01 do 2038-01-19 03:14:07. |
BOOLEAN / BOOL |
Wartość logiczna TRUE (1) lub FALSE (0). Alias typu TINYINT(1). |
ENUM(...) |
Wybór z listy, np. ENUM('tak','nie'). Maks. 65535 unikalnych wartości. |
Przegląd modeli danych
Kiedy zajmujemy się tworzeniem takich wielkich zbiorów danych, to tak naprawdę modelujemy rzeczywistość. Tworzymy model, czyli abstrakcyjną, wirtualną reprezentację rzeczywistego świata. Model danych to zatem integralny zbiór zasad opisujących stan reprezentowanych obiektów, ich zachowania oraz istniejące powiązania logiczne pomiędzy fragmentami symulowanego świata.
Najpopularniejszym współczesnym sposobem reprezentacji rzeczywistości stosowanym we współczesnych bazach danych jest tzw. model relacyjny, którego ideę opisał w 1985 roku Edgar Frank Codd w słynnej pracy pt. “Model relacyjny w zarządzaniu bazami danych”. Przedstawione przez autora tzw. dwanaście postulatów Codda zrewolucjonizowało sposób projektowania systemów zarządzających bazami danych. Warto wymienić wszystkie rozwijane przez lata modele danych, bo czasem mogą się pojawić na ten temat pytania w części teoretycznej egzaminu INF.03:
- Model jednorodny – najprostszy, przewidujący użycie jednego pojemnika przechowującego wszystkie dane. Przykładem może być alfabetyczny spis pracowników firmy albo książka telefoniczna. Największe wady takiego sposobu modelowania to długi czas dostępu do informacji oraz często występująca redundancja (nadmiarowość) informacji.
- Model hierarchiczny – oparty na strukturze odwróconego drzewa, czyli takiego w którym korzeń znajduje się na szczycie hierarchii. W bazie istnieją węzły nadrzędne i podrzędne (czyli właśnie hierarchia). Zasada drzewa głosi, iż jeden ojciec może mieć wiele dzieci, ale każde dziecko ma tylko jednego ojca. Przykładem wykorzystania tego modelu był system IBM IMS, zapoczątkowany w roku 1966 na potrzeby programu Apollo.
- Model obiektowy – zrealizowany zgodnie z paradygmatem programowania obiektowego. Rzeczywistość reprezentujemy za pomocą obiektów tworzonych na podstawie klas. Każdy obiekt ma atrybuty opisujące jego stan. Istnieją także metody, czyli specjalne funkcje należące do klas. Metody reprezentują zachowanie obiektu oraz określają zasady dostępu do jego wartości składowych, zapewniając dodatkową możliwość hermetyzacji danych w celu ochrony ich integralności. Interakcja z obiektami jest możliwa tylko przez udostępniony w klasach interfejs. Przykłady użycia tego modelu sięgają lat 70. XX wieku.
- Model sieciowy – bazował na strukturze hierarchicznej (drzewiastej), lecz wprowadził pewne modyfikacje – używało się w nim tzw. typów rekordów i kolekcji, zaś reprezentacja tych typów oraz powiązań miała postać grafu zorientowanego, nazywanego siecią (stąd nazwa modelu). Ten model został zaadoptowany w 1969 r. przez grupę CODASYL Data Base Task Group, dzięki czemu w latach 70. XX wieku znalazł praktyczne zastosowania. Z czasem jednak model został ostatecznie zastąpiony przez architekturę relacyjną.
- Model relacyjny – najpopularniejszy obecnie, opracowany przez Edgara Franka Codda, sposób reprezentacji fragmentu otaczającej nas rzeczywistości. Fundamentem modelu jest matematyczne pojęcie relacji, występujące w teorii mnogości, a związane nierozerwalnie z tzw. iloczynem kartezjańskim. W relacyjnych bazach danych nie używamy klas ani obiektów, tylko encji oraz instancji. Podstawową formą przechowywania danych jest tabela (relacja) zbudowana z kolumn (atrybutów) oraz wierszy (rekordów, krotek).
- Model relacyjno‑obiektowy – kompromis pomiędzy relacyjnymi, a obiektowymi bazami danych, łatwiejszy w implementacji od czystego modelu obiektowego. Idea modelu polega na tym, że operujemy na danych tak jak na obiektach, czyli z możliwością zaprogramowania własnych metod, używających technik obiektowych (na przykład dziedziczenia, polimorfizmu). Jednak wewnętrzny mechanizm przechowywania danych jest relacyjny. Można ująć to następująco: mechanizmy obiektowe wykorzystywane są wewnątrz relacyjnej bazy danych.
Integralność (spójność) danych
Jest to właściwość zbioru informacji, która gwarantuje, że dane nie mogą zostać usunięte, zniekształcone bądź zmienione w nieautoryzowany sposób lub podczas wykonywania na nich operacji. Ochrona integralności jest jedną z podstawowych funkcji systemu zarządzania bazami danych (DBMS). Aby spójność danych znajdujących się w bazie była zachowana, potrzebne jest uwzględnienie dwóch głównych kryteriów – dokładności oraz prawdziwości informacji:
- Dokładność – informacje zgromadzone w bazie danych stanowią model rzeczywistości, czyli reprezentację pewnego fragmentu otaczającego nas świata. Dokładność oznacza przechowanie informacji jednoznacznie odzwierciedlających stan oraz zachowanie reprezentowanego obiektu, odrzucając wzajemnie wykluczające się scenariusze logiczne oraz konflikty typu (rodzaju) przechowywanej wartości.
- Prawdziwość – zbiór informacji musi zawierać dane aktualne, czyli odpowiednio zmieniające się wskutek zmian zachodzących w modelowanej rzeczywistości. Wymóg prawdziwości danych narzuca więc systemowi zarządzania bazą danych konieczność istnienia mechanizmów bezpiecznego aktualizowania zgromadzonych rekordów.
Resumując: zbiór informacji nie jest spójny, jeśli dane nie odpowiadają modelowanej rzeczywistości – szczególnie, że może ona ulegać zmianom.
Więzy integralności
Szczególnym rodzajem ograniczeń, które można nałożyć na dane, są tzw. więzy integralności. Zapobiegają one powstawaniu rekordów nieprawidłowych lub odłączonych, czyli niespełniających wszystkich istniejących powiązań pomiędzy atrybutami tabel. Rodzaje więzów integralności:
-
Więzy statyczne – ograniczenia stanu bieżącego, wykluczające niedopuszczalne wartości – na przykład sprawdzenie reguły: “pensja pracownika jest większa niż zero”,
-
Więzy dynamiczne – ograniczenia przejść między stanami, przeciwdziałające niedopuszczalnym zmianom – na przykład sprawdzenie reguły: “wiek pracownika nie może maleć“. W wielu ujęciach tematu integralności nazywane także więzami przejść.
Podsumowanie
- SQL to język zapytań do baz danych – zapisujemy w nim kwerendy do systemu DBMS.
- Baza danych to uporządkowany zbiór informacji, najczęściej przechowywany w tabelach.
- DBMS (ang. Database Management System) to oprogramowanie zarządzające bazami danych (np. MySQL, MariaDB, PostgreSQL).
- Tabela składa się z rekordów (wierszy) oraz atrybutów (kolumn).
- Encja (lub klasa) to zestaw atrybutów danego obiektu, a rekord to jej instancja.
- Różne pojęcia (np. klasa, encja, tabela) mogą oznaczać to samo w zależności od kontekstu (bazy danych, programowanie, teoria relacji).
- SQL dzieli się na cztery podzbiory:
DCL– kontrola dostępu (GRANT, REVOKE),DDL– definicja struktury (CREATE, ALTER),DML– manipulacja danymi (INSERT, UPDATE),DQL– zapytania do danych (SELECT).
Primary key– klucz główny, jednoznacznie identyfikuje rekord, jest unikalny i nie może być pusty.Foreign key– klucz obcy, wskazuje na klucz główny w innej tabeli, tworzy powiązanie logiczne.- Rodzaje relacji między tabelami:
- 1:1 – jeden do jednego,
- 1:N – jeden do wielu,
- N:M – wiele do wielu (wymaga tabeli pośredniczącej).
- Pakiet
XAMPPpozwala uruchomić lokalny serwer z Apache, MariaDB, PHP i phpMyAdmin. - Typy danych SQL (przykłady):
INT– liczba całkowita,VARCHAR(n)– tekst o zmiennej długości,DATE– data,BOOLEAN– wartość logiczna.
- Akronim (skrót utworzony z pierwszych liter słów) CRUD oznacza podstawowe operacje bazodanowe: Create, Read, Update, Delete.
- Współcześnie używanym modelem danych jest model relacyjny. Inne modele to: jednorodny, hierarchiczny, obiektowy, sieciowy, relacyjno-obiektowy.
- Spójność (integralność) danych to – najprościej mówiąc – zgodność modelu z rzeczywistością. Jest ona zapewniona poprzez kryteria dokładności oraz prawdziwości informacji.
- Więzy integralności (statyczne i dynamiczne) to ograniczenia “pilnujące” spójności danych w modelu.